[AI윤리] 고릴라를 금지한 구글포토 수업이야기 -3-

[AI윤리] 고릴라를 금지한 구글포토 수업이야기 -3-
지난이야기
1탄 : https://pangguinland.tistory.com/332
2탄 : https://pangguinland.tistory.com/334
포스팅을 마무리지어야하는데 자꾸 길어진다.
오늘 이야기
2. 검색을 통해 새롭게 알게 된 사실과 견해
(#1은 지난 포스팅에서 다룸)
- #2 수집된 데이터의 문제, 고릴라로 분류된 원인 추측
: 데이터 세트를 늘리면, 윤리적 문제는 사라지는가? - "아니오"
- #3 조치와 그 이후
: 윤리적인 문제를 해결하는 적절한 조치
3. 그 이후 수업과 나의 결론
#2 수집된 데이터의 문제, 고릴라로 분류된 원인 추측
#1에서는 인간의 인식 과정과 다른 인공지능의 분류에 대해서 알아보았다. 그리고 분류 모델의 한계와 분류 결과에 대한 인간중심적인 접근을 경계해야한다는 생각을 얻었다. 윤리 수업에서 단지 '인공지능이 나빴다.'는 말은 위험하고 불가능한 것이었다.
그러나 이 사례를 단지 우리의 관점('인공지능이 이렇게나 비윤리적이다니!')을 바꾸고, 이미지 인식 과정은 한계가 있을 수 밖에 없다는 것으로 조사를 마무리하지 않기로 했다. 데이터 세트는 한 번 살펴볼 필요가 있었다.
찾다보니 '흑인 이미지 데이터가 적었겠지.'라고 넘겨짚으려 했으나, 생각보다 많은 공부거리를 던져 주는 것들이 많았다.
우선, 학습 데이터 세트에 대한 의견들을 살펴보자.

"학습데이터의 다양성 부족" "사전 테스트 누락"
this initial set of training data almost certained no black people, and likey contained gorillas.
이 초기 훈련 데이터 세트에는 흑인이 거의 없고 고릴라가 포함되어 있는 것으로 확인되었습니다. 이 때문에
거짓 양성 (false positive : 실제 음성인데 결과는 양성으로 예측하는 것. 고릴라가 아닌데, 고릴라로 예측한다.)이 나타납니다.
흑인에 대한 이미지 데이터가 없으니 고릴라로 분류하는 결과가 나타났다라는 의견, 사전에 서비스를 배포하기전 테스트를 했어야하는데, 일부 데이터에 대하여만 테스트를 했을 것이다라는 의견이 있었다.
: 데이터 세트를 늘리면, 윤리적 문제는 사라지는가? - "아니오"
그렇다면 많은 데이터를 훈련하면 해결될까? 흥미로운 연구 결과가 있다.
The Dark Side of Dataset Scaling: Evaluating Racial Classification in Multimodal Models(2024, Abeba Birhane)에 따르면, 데이터셋의 규모를 증가시켰을때, 인간 이미지를 침팬지, 고릴라, 오랑우탄과 같은 비인간 클래스로 잘못 분류하는 확률이 줄었다.
그러나, 동시에 다른 문제가 나타났다. 이 논문에서는 큰 모델(4억2천7백만 개의 파라미터)과 작은 모델(1억 5천만 개)를 구분해서 실험하였다. 큰 모델에서 데이터 셋의 규모를 증가시켰을때, 인간 이미지를 범죄자 같은 공격적 클래스로 잘못 분류하는 확률이 증가한 것이다. (작은 모델에서는 잘못 분류할 확률이 개선되었다.)
(큰 모델에서는 특정 인종 그룹(흑인, 라틴계)을 범죄자로 잘못 분류하는 경향이 함께 증가한 것. 논문출처 : https://arxiv.org/html/2405.04623v1#S4)
이를 통해 보면, 모델의 크기와 데이터셋의 규모는 복잡한 관계라는 것이다. 더불어 이는 데이터 셋을 늘리는 과정에서 해결하려던 문제가 나아지더라도 새로운 윤리적 문제를 가지고 올 수 있음을 시사한다.
'AI의 편향을 해결하기 위해서는 다양성을 가진 '더 많은' 데이터를 학습시켜야 한다.'라고만 설명하기에는 무리가 있다는 것을 알았다.
- #3 조치와 그 이후
2015년 6월 28일 저녁 6시 22분, 고릴라로 분류된 흑인 커플의 사진이 트위터에 올라왔다. 흑인 프로그래머 재키 엘신과 그의 여자친구가 찍은 사진에, 하얀 글씨로 고릴라들이라는 라벨이 붙은 이 이미지는 순식간에 여기저기 퍼져나갔다.
구글은 매우 빠르게 대응했다. 2시간도 채 되지 않아서, 총 책임자가 "문제의 원인을 찾기위해 계정에 접속해도 되겠느냐"며 엘신의 트위터에 메시지를 달았다. 무려 일요일이었는데도 말이다. 얼마나 순식간에 트위터를 휘집어 놓았던 것인지 상상해볼 수 있다. 구글은 바로 다음날 해결 패치를 내고, 이런 오류가 흑인에게만 해당하지 않음을 강조하였다. 엘신은 '신속한 대응에 감사드린다.'며 답했다.
당시에 구글의 사과와 재빠른 조치는 좋은 선례로 기사에 담겨졌다.
Google’s photo app still can’t find gorillas. And neither can Apple’s
Google’s photo app still can’t find gorillas. And neither can Apple’s | eKathimerini.com
When Google released its stand-alone Photos app in May 2015, people were wowed by what it could do: analyze images to label the people, places and things in them, an astounding consumer offering at the time.
www.ekathimerini.com
그러나 2023년 기사에서 알 수 있듯이 구글 포토 앱은 고릴라 등 영장류 관련 라벨이 아예 작동하지 않는다. 신속한 대처는 아예 분류를 막는 방식이었다. 애플도 마찬가지다. 2015년으로부터 한참 시간이 흐른 지금은 개선되었을까?
윤리적인 문제를 해결하는 적절한 조치
직접 2023년 10월, 2024년 8월에도 구글 포토앱을 실행해 보았는데, 다른 동물 이미지는 분류된 이름들이 나타나지만, 고릴라 및 영장류 이미지들에는 놀랍게도 전혀 등장하지 않는다.
영장류가 아닌 다른 동물들의 이미지를 검색하는 경우


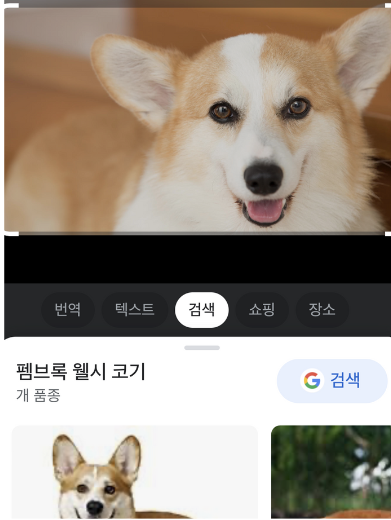


영장류 이미지를 검색하는 경우

마땅한 조치였는지도 모른다. 2024년까지 이미지 인식이 놀랍게 발전하는 와중에도 고릴라를 고릴라라고 선뜻 말하지 않는 과묵함(?)을 장착한 것이다.
이러한 사실을 알기 전에는 '조치'를 막연히 문제를 해결해낸 더 발전된 기술이라고 예상했다. 그러나 논란을 일으킬 수 있는 고릴라 라벨을 숨기는 것으로 적절한, 재빠르고 성숙한 조치가 완성되었다.
윤리적인 문제에 대해서 우리가 합의할 수 있는 또는 막을 수 있는 '적절한' 해결책은 더 발전된 기술이 아닐 수도 있다는 점이 인상적이다.
3. 그 이후 수업과 나의 결론
그 수업 이후 사례에 대해 더 찾아보면서, 내가 이 사례에 대해서 굉장히 많은 부분을 모르고 있다는 걸 느꼈다. 사례의 출발부터 도착까지 알아야한다.
차근차근 이 사건이 생겨난 원인에 대한 추측들이나 관련 기사, 문제가 발생하고 난 뒤 사용자의 행동, 그리고 구글의 반응과 조치를 알아가면서 느낀 것은 인공지능 서비스 하나가 만들어지는 단계, 테스트 및 적용되는 단계, 활용되고 개선되는 단계, 즉 인공지능의 생애 주기 내내 고민이 있어야 한다는 점이다.
인공지능은 윤리적으로 잘못을 저지를 수 없었다. 학생의 질문대로 '인공지능이 잘 한 것'은 맞다.
그러나 인간의 행동에서 아쉬움이 있다. 나는 '나쁘다'라는 설명과 함께 이 사례의 사진을 보여주고 넘어갈 것이 아니라, 이 하나의 사례를 천천히 살펴보았어야 했다. 이 서비스가 만들어지고, 문제가 발생하고, 마무리되기까지의 과정을 살펴보고 같이 고민해보아야 했다.
과정을 같이 들었다면 아이들에게 이런 질문들을 전하며 함께 고민해볼 수 있었다.
<설계 및 개발>
- 이 서비스는 어떤 기능을 제공하려고 했을까?
- 이 서비스에서 분류는 필요한 것일까?
* 인공지능 설계 과정에서 '이 문제를 해결하기 위해 인공지능이 필요한가'를 확인해보라는 점검표를 본적있다. 요즘 참 필요한 질문이다.
- *이 서비스에서 인종을 분류하는 것은 필요한가? 인종을 분류하는 것이 가능한가?
- 학습 데이터에서 부족한 부분이 무엇이었을까?
- 다양한 집단의 의견을 듣고, 대표성을 담으려는 노력은 왜 필요할까?
<적용 및 피드백>
- 사용자에게 모델의 작동 원리나 분류 기준을 설명해주었다면, 사용자의 반응은 달랐을까?
- 사용자가 트위터에 올리는 방법을 택한 이유는 무엇일까? 오류나 문제 상황이 발생했을 때 사용자로부터 피드백을 받을 방법이 있었을까?
- 서비스를 제공하기 전이나 제공 중에 위험을 예방하려는 노력이나 장치가 있었나?
- 적극적으로 해결하려고 노력했나? 어떤 점에서 충분히 해결되었다고 생각하나? 그렇지 않다면 어떤 부분은 해결되지 않았다고 생각하나?
- 이 사례는 사용자나 개발자에게 어떤 영향을 줄까?
* 인종이라는 분류는 가능한가? 포스팅을 마무리 지으려는 즈음에 모든 것을 원점에 놓는 질문을 보았다.
- 이 서비스에서 인종을 분류하는 것은 필요한가? 인종을 분류하는 것이 가능한가?
서비스에 따라서, 목적에 따라서 피부색에 따른 분류나 유전적인 특성을 분류하는 것은 필요할 수 있다. (의료 분야 등) 그런데 '인종'이라는 분류에 대한 비판의 글을 읽고 나니, 한 가족 안에서도 다채로운 피부색을 black, white로 묶는 것이 적합한지 의문이 든다. 고릴라로 분류되는 것은 왜 불쾌한가에 대한 이야기나 분류 자체에 대하여 문제를 제기하면 또 생각거리가 산더미다.
* 이 수업 이후 다음 해에 이 생각들은 수업자료를 만드는 데에 잘 녹아들게 되었다.
질문을 던지는 기준을 사람이 중심이 되는 「인공지능(ai) 윤리기준」 2020.12. 에서 아이디어를 얻었다. 10가지 요건은 아주 든든한 기준점이 되어준다. 그리고 '질문'을 중심으로 윤리적 감수성을 기르는 수업을 구성해보았다. 외부 작업에 참여하면서 덕분에 생각으로만 남을 아이디어가 자료로 정리되었고, 네이버 생성형 인공지능 윤리교재에 반영되었다. 진짜 묵혀버린 오래된 생각이었는데, 종결(?)되지 못한채 버려지지 않아 뿌듯하다.
드디어 포스팅을 마무리한다!