
용어를 알아보자!
k-nn 알고리즘에 대해 좀 더 알아보던 중 '인스턴스 기반 학습 (instance based learning) 중 하나라는 설명을 읽고 인스턴스의 의미에 대해 찾아보았다. 왜 이제서야 접한 것인지 신기할 정도로 자주 쓰이는 용어였다.
겸사겸사 오늘 몇 가지 용어들과 함께 정리를 해보려한다!
설명을 위해 붓꽃 데이터를 함께 살펴볼 예정이다.
1 데이터 셋 data set : 모든 데이터의 집합
붓꽃 데이터 셋(data set) 안에는 150개의 붓꽃들의 데이터가 들어있다.

2 인스턴스 (instance) ≒ 사례, 샘플 (example, case, sample) ≒ 레코드 (record) ≒ 데이터 포인트 (datapoint) ≒ 행 (row) : 개별 데이터
위의 나열한 용어들은 여러 데이터들에서 개별 데이터를 지칭할 때 쓰인다
따라서 위의 그림에서 붓꽃데이터는 150개의 레코드가 모인 셋트라고 설명한 것이다.
인스턴스 또한 sepal_length / sepal_width / patal_length / petal_width / species 이라는 여러 속성들을 지닌 하나의 단위 데이터, 개별 데이터를 의미한다.
데이터 포인트는 데이터가 다차원 공간 안에서 위치로 표현될 때 사용되는 용어이다. 예를 들어 아래와 같이 2가지 특성을 지닌 데이터를 2차원의 그래프로 나타내었을때 한 점이 개별 데이터 하나를 의미하며, 이를 데이터 포인트라고 부를 수 있다.

붓꽃 데이터를 코랩에서 불러와서 가장 처음 데이터부터 5개까지만 불러와보기 위해 iris.head() 치면
아래처럼 열 (Column)과 행 (row)을 여러 개 가진 표가 나타난다.
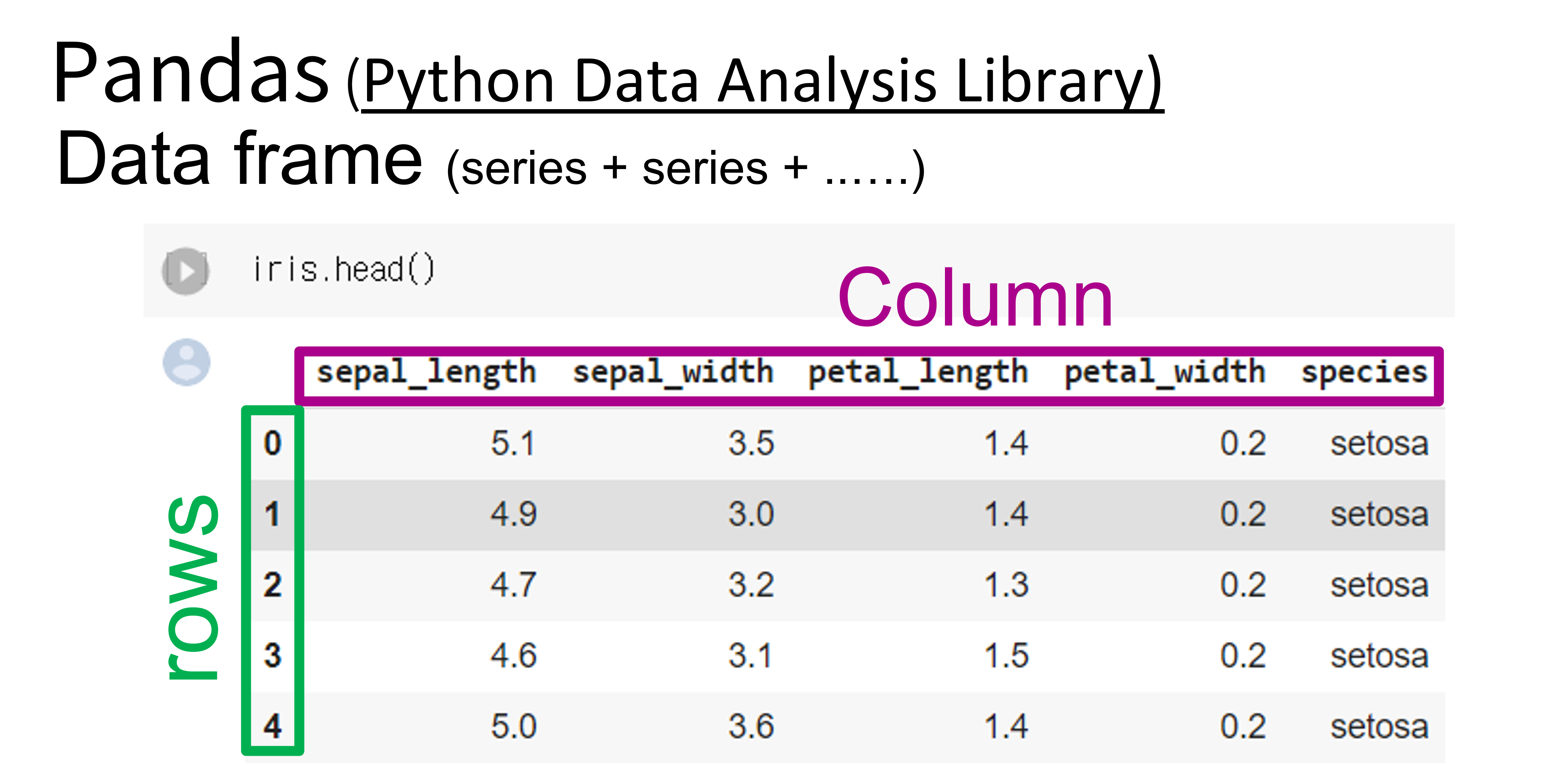
3 열 (Column) ≒ 속성 (attribute) ≒ 변수 (variable) ≒ 필드 (field)
위 그림에서 5개의 열이 보인다.
각각을 보면 sepal_length sepal_width petal_length petal_width 라는 4가지 특성 (feature)을 담은 열과 species 라는 1가지 라벨(=정답, 목표, 타켓)의 열이 있다. 총 5가지 속성(attribute)을 갖고 있다.
5개의 열은 5가지의 속성을 보여주며, 5개의 속성에는 4가지 특성 + 1가지 라벨이 있는 것이다.
꽃잎의 생김새 (petal이 꽃잎이고 sepal은 꽃받침이라고 한다. 사실ㅎㅎ 사진을 봐도 꽃받침이 뭔지 헷갈린다) 4가지를 가지고 종을 분류할 생각이기 때문에, 종(species)은 타겟, 목표, 정답이자 라벨이라고 할 수 있는 열이 된다.
다만, 붓꽃데이터 셋처럼 라벨이 함께 들어있는 데이터와 달리, 특성(feature)만 담은 데이터 셋도 있다.

4 특성 (feature) ≒ 독립변수 (indepemdant variable) ≒ 입력 (input) ≒ 차원 (dimension)
특성은 머신러닝에서 학습(훈련)을 위해 선택된 속성이라고 할 수 있다.
아래 벤다이어그램으로 보면, 속성이 미묘하게 좀 더 넒은 범위의 의미라는 뜻이다.
속성이나 특성은 머신러닝 모델을 만들기 위해 입력 (input)으로 사용되는 데이터 포인트의 특징, 성질(property)을 뜻하는 공통점이 있다.
다만, 속성 (attribute)에서 분류나 예측 등을 위해 도움이 되리라 선택한 일부의 속성들이 특성 (feature)이 되는 것이다.
가령, 고객의 구매여부를 예측할 때, 고객 데이터에서 '성별', '나이', ''이름' 등의 여러 속성 중 '성별'과 '나이'는 예측을 위한 중요한 속성으로 선정되어 학습에 쓰일 수 있으나 '이름'은 특성으로 선택되지 않을 수 있다.

데이터가 인과관계를 같는 경우에는 이러한 특성은 종속변수를 일으키는 독립변수로 부를 수도 있고, 그래프상에서 차원으로 나타날 수도 있다.
5 라벨 (label) ≒ 클래스 (class) ≒ 타켓(target) ≒ 종속변수 (dependant variable)
라벨(정답, 목표)이 있는 데이터를 활용하는 지도학습을 떠올리면 위 용어들의 각각의 의미는 쉽게 와닿는다. 다만, 각각의 용어가 사용되는 상황은 조금 차이가 있다.
클래스는 분류를 목적으로 할 경우 사용된다. 성별이나 당선여부, 꽃의 종류 등과 같이 나뉘는 카테고리라고 할 수 있다.
종속변수는 데이터 셋이 인과관계를 가진 경우에 사용된다. 이러저러한 특성(feature)들이 독립변수(independant variable)가 되는 데이터 셋트일 때 종속변수라는 용어를 쓸 수 있다.
나름 미묘한 차이나 겹치는 용어들을 인스턴스를 계기로 모아보았다. 나와 같은 초보들에게는 약간의 방향표가 되어주리라 생각한다! 이 포스팅에 이어서 아래 블로그에 들려서 다른 용어들도 구경해보길!
이분은 아주 표로 쌈빡하게 정리하셨다!
https://realblack0.github.io/2020/03/23/thesaurus.html#footnote_2
'AI , 컴퓨터 , 대학원 > 딥러닝 공부' 카테고리의 다른 글
| 14주차 EOS 란? (자연어처리) / np.zeros() / iterrows (0) | 2021.05.29 |
|---|---|
| KNN (K-최근접 알고리즘) 시각화 학습 사이트 (0) | 2021.03.13 |
| 파이썬으로 배우는 알고리즘 트레이딩 (0) | 2021.02.15 |

