인공지능 에이전트의 신뢰 회복에서의 의인화, 암묵적 이론, 및 사과 귀인의 효과 [논문리뷰]
The Effect of Anthropomorphism, Implicit Theory, and Apology Attribution on the Trust Repair of Artificial Intelligent Agent 김태년 (2021)
아래는 먼저 읽어보면 좋은 블로그 글입니다. 이 포스팅은 공부를 위해 정리한 내용이다보니 조금 두서없는 포스팅일 수 있습니다. 혹여 흥미로운 제안이나 가설을 발견하셨다면 논문 원문을 꼭 살펴주시길 바랍니다!
CASA 패러다임 (Computers are .. : 네이버블로그 (naver.com)
CASA 패러다임 (Computers are Social Actors)
인간과 컴퓨터의 관계가 근본적으로 ‘사회적이라는 것’을 보여준다면 우리는 인간과 컴퓨터의 상호작용에...
blog.naver.com
목차
1. 개요
2. 결과 및 느낀점
3. 논문 내용 (문헌연구/결과) 발췌 요약
1. 개요
본 연구는 인공지능과 인간의 관계에서 필수적인 신뢰에 대하여 주목한다. 접했던 많은 논문들이 신뢰를 형성하고 지속적인 이용을 유도하는 방법을 논하는데 이 논문에서는 신뢰를 잃은 후의 회복에 대하여 집중한다.
참여자는 총 5라운드에 걸쳐 투자게임에 참여한다. 이때 회사에 관한 정보와 함께 인공지능의 제안이 제공된다. 선택 후에는 각 라운드마다 결과가 나타나며 인공지능의 제안이 효과적이었는지를 확인할 수 있다.
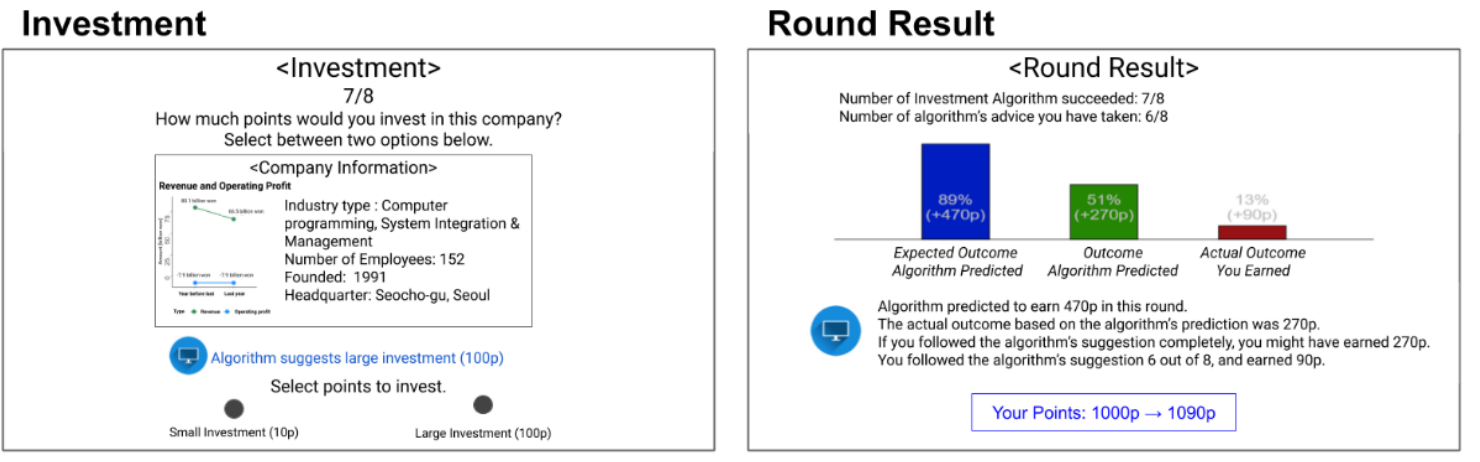
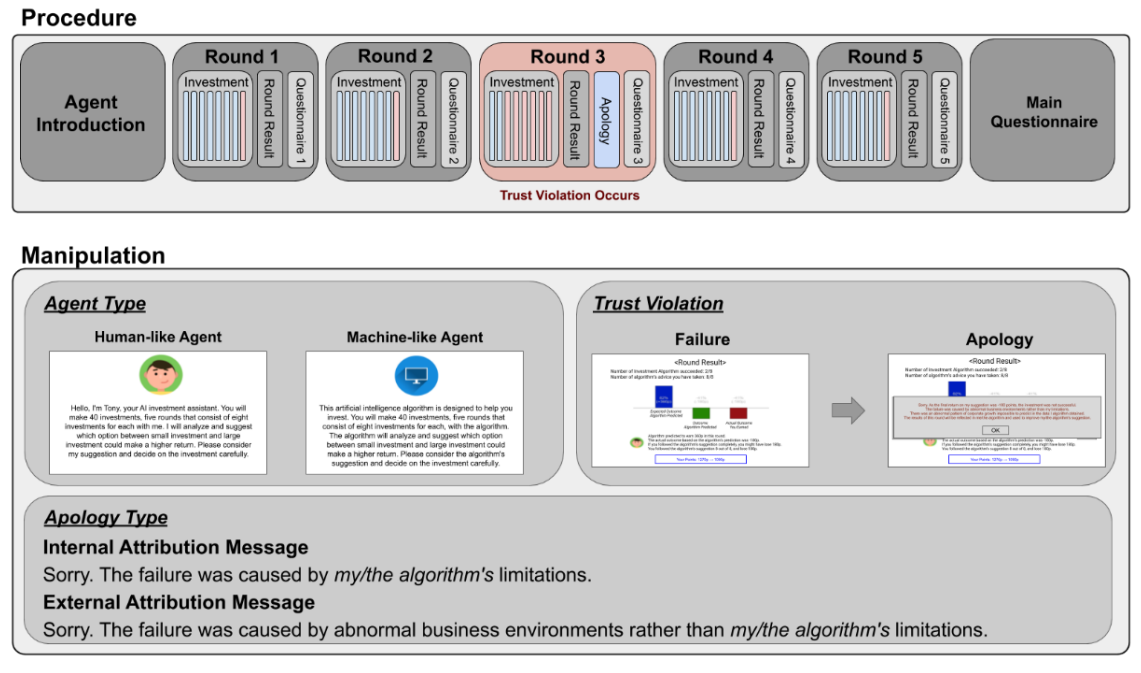
이때 인공지능 에이전트 타입은 2가지로 (1)인간에 가까운 형태로 나타나 제안을 하는 경우(프로필이미지, 자기소개, 일인칭 대명사 사용)와 (2)기계에 가까운 형태로 나타나는 경우로 나뉜다.
중간 3라운드에서 인공지능의 제안이 적당하지 않아 신뢰를 잃은 뒤, 이후의 단계에서 이를 사과 유형(내부귀인 : 나,알고리즘의 한계에 귀인/ 외부귀인 : 비정상적인 외부 환경환경 영향에 귀인)과 에이전트 유형에 따라서 신뢰도가 회복되는 정도를 비교한다. 그리고 이후 인공지능의 제안을 받아들이는 정도를 비교한다.
2. 결과 및 느낀점
(가설과 결과에 대한 자세한 내용은 3. 논문 내용 발췌 요약에 있습니다.)
-논문 일부-
여러 전략 중 (기계-내부귀인, 기계-외부귀인, 사람-내부귀인, 사람-외부귀인 중에서) [기계에 가까운]의 경우 잘못을 인정하는 내부 귀인을 택한 경우가 가장 신뢰도 회복에 도움이 되지 않았다. 이는 아마도 사람들이 컴퓨터가 책임을 지는 것을 부자연스럽게 느끼거나, 기계가 자신의 한계를 인정할 때 기계에 대한 기대를 잃기 때문일 수 있다.
미미한 수준이나, 내부 귀인(자신의 잘못을 인정)으로 사과를 하는 경우 더 사람에 가깝다고 느끼는 경향이 있었다. 이는 '외모'와 '행동'에 의한 의인화를 구별한 연구와 잘 일치한다. (de Visser 등, 2016) 이 연구에서는 의인화를 위해 외모를 조작했다. 그러나 내부 귀인처럼 책임을 지는 행동은 인간만이 할 수 있는 일이라고 생각하기 때문에 이것이 행동에 의한 의인화로 간주될 수 있다.
기계가 사과를 한다는 등의 불협화음이 신뢰차원에 영향을 미쳤을 수 있다. 그러나 자신의 한계를 인정하는 [기계같은]인공지능의 경우가 신뢰 회복에 가장 비효율적인 이유는 여기에서 알 수 없다. 의인화에 따른 불협화음이 그 원인일 수도 있지만 다른 설명이 가능할 수도 있다.

- 본 연구에서 인공지능을 의인화한 방법은 2가지였다.
에이전트의 프로필 이미지를 통한 '외모'에 의한 의인화뿐만 아니라 인공지능의 발화 내용 및 사과 과정에서 간주되는 '행동'에 의한 의인화로 크게 2가지로 나뉜다.
기계같은 인공지능이 사람만이 할 수 있는 사과를 한다는 것이 문제였을 것이라는 부분이 인상깊다. [기계같은 인공지능 유형]의 경우 이 실험에서처럼 '사과하는 행동'없이 '오류 확인 및 오류 세부내용 제시'로 끝냈다면 결과는 달라졌을까?
의문을 더하면,
기계와 같은 유형은 프로필 이미지와 일부 발화 내용을 통해 (일인칭을 사용하지 않는 등) 의인화되지 않은 경우를 유도했지만, 사과하는 행동뿐만 아니라, 대화를 통해 인간과 상호작용하는 과정에서 불가피하게 의인화되었을 수 있다.
그리고 투자게임을 함께 하며 상호작용하는 관계, 협업의 관계에서 이미 의인화가 이루어지는 것은 아닌가? 에이전트가 아무리 프로필 사진을 컴퓨터로 하였다고 하더라도. 일단 CASA패러다임을 더 공부해야할듯하다. 아래 블로그 아주 정리를 잘해주셨음.
CASA 패러다임 (Computers are Social Actors)
인간과 컴퓨터의 관계가 근본적으로 ‘사회적이라는 것’을 보여준다면 우리는 인간과 컴퓨터의 상호작용에...
blog.naver.com
CASA패러다임에서는 사람들이 컴퓨터와의 관계에 사람사이의 사회적 규칙을 적용한다고 말한다. 즉, 사회적 관계에서 신뢰회복에 쓰이는 기술이 컴퓨터와 인간 관계에서도 유효할 것이라고 가정할 수 있다. 그렇다면 또 어떤 사회적 기술이 효과가 있을까?

3. 논문 내용 (문헌연구/결과) 발췌 요약
문헌연구
2.1 Literacture Review
예를 들어, 공과 나스(2007)는 에이전트의 얼굴과 목소리에서 인간과 기계의 유사성이 일치하지 않으면 에이전트를 평가할 때 정보 처리가 지연되는 반면, 적절한 일치가 컴퓨터에 대한 사람들의 사회적 반응을 촉진한다는 것을 발견했다.
People assign less responsibility and blame the transgressor less when given external causes for poor performance than when the transgressor acknowledges his internal limitations.
According to the CASA paradigm, people unknowingly apply social rules in their relationships to computers (Nass and Moon, 2000; Nass et al., 1995; Reeves and Nass, 1996). Thus, it can be postulated that a computer’s apology would be as effective as a human’s apology in trust repair (Bottom et al., 2002; Lewicki et al., 1996; Ohbuchi et al., 1989).
However, a recent study of the CASA paradigm argues that it is also possible that people have distinctive mental models for intelligent agents that are different from the ones utilized for humans (Gambino et al., 2020).
결과는 사람들이 컴퓨터를 인식하는 방법과 어떤 사과 유형(즉, 내부 귀인, 외부 귀인)이 더 효율적으로 신뢰를 회복하는지 결정하는 데 의인화의 중요성을 강조합니다.
방법
2.2 Method
- 의인화를 위한 조작 방법
의인화를 위해 소개내용 / 이미지 / 이름 / 3가지 요소를 설정하여 인간에 가까운 인공지능과 기계에 가까운 인공지능의 대화내용에 차이를 두고 참여자들에게 제시함.
1. [인간에 가까운] 인공지능 조건의 경우
프로필 이미지가 사람 캐릭터이며, 이름을 가지고 있고, 인사를 하며, 1인칭 대명사를 (I'm ~ )사용한 문장으로 과정을 소개하고 도움을 줄 것임을 안내함.
”Hello, I’m Tony, your AI investment assistant. You will make 40 investments, five rounds that consist of eight investments for each with me. (...) I will analyze and suggest which option between small investment and large investment could make a higher return. Please consider my suggestion and decide on the investment carefully.”
2. [기계에 가까운] 인공지능 조건의 경우
프로필 이미지가 컴퓨터이며, 스스로를 인공지능 알고리즘으로 지칭하고, 인사를 건내지 않음.
"This artificial intelligence algorithm is designed to help you invest. You will make 40 investments, five rounds that consist of eight investments for each, with the algorithm. (...) The algorithm will analyze and suggest which option between small investment and large investment could make a higher return. Please consider the algorithm’s suggestion and decide on the investment carefully.”
- 신뢰를 잃은 후 사과 방법
1. [내부 귀인]
[인간에 가까운], [기계에 가까운] 에이전트가 각각 "'나의' / '알고리즘의' 한계로 인한 것이다."라고 설명함.
Sorry. As the final return on my/the algorithm’s suggestion was XXX point, the investment was not successful. The failure was caused by my/the algorithm’s limitations. There was a limitation to my/the
algorithm’s ability because I/the algorithm couldn’t get enough data to predict the growth pattern of a company
2. [외부 귀인]
[인간에 가까운], [기계에 가까운] 에이전트가 각각 부분적인 책임을 인정하면서 외부의 비정상적인 환경으로 인한 영향에 책임을 돌림.
Sorry. As the final return on my/the algorithm’s suggestion was XXX points, the investment was not successful. The failure was caused by abnormal business environments rather than my/the algorithm’s limitations. There was an abnormal pattern of corporate growth impossible to predict in the
data I/the algorithm obtained.
외부귀인, 내부귀인 두 경우에 공통적으로 이후 학습을 통해 더 나은 수행을 보여줄 것을 약속 했음.
결과
2.3 Results
- [초기 신뢰도 형성 Initial Trust-building] 측면에서
가설1 : 초기 신뢰도는 에이전트를 [인간에 가까운]으로 인식할 때가 [기계에 가까운]보다 높을 것이다.
H1. Initial trust would be higher in a machine-like agent and lower in a human-like agent.
> 결과 : 의인화 여부에 따른 유의미한 차이가 나타나지 않았음.
- [인지된 신뢰] 에이전트가 신뢰를 잃게 만드는 제안을 한 뒤의 신뢰도 비교
가설2 : 인간/기계에 가까운 유형에 따라 효과적인 귀인 방법이 있을 것이다.
H2. The use of anthropomorphism will determine the effectiveness of distinctive types of apology (i.e., internal or external-attribution apology).
H2a. Trust repair would be more effective when a machine-like agent
apologizes with an external-attribution than with an internal-attribution.
H2b. Trust repair would be more effective when a human-like agent
apologizes with an internal-attribution than with an external-attribution.
In sum, the result showed that trust in the Machine-like–External condition was damaged less than for any other agent after the violation. > H2a를 뒷받침함
> 결과(1) : [기계에 가까운 인공지능-외부 귀인]의 경우 다른 경우보다 신뢰를 잃는 정도가 가장 적었음.
*(다른 경우란 [기계에 가까운-내부 귀인], [사람에 가까운-내부귀인], [사람에 가까운-외부귀인] )
> 결과(2) : [외부귀인]이 [내부귀인]보다 신뢰를 잃는 정도가 적었음.
> 결과(3) : [사람에 가까운]의 경우 내부귀인이냐 외부귀인이냐의 사과 유형에 따른 차이가 없었음.
- [행동 신뢰 Behavioral Trust ] 신뢰를 잃은 이후 제안을 따라 행동하는 정도 비교
> 결과 : 다시 제안을 받았을 때 [사람에 가까운-내부귀인]의 제안을 더 잘 따름. > H2b를 뒷받침함
기계 유사 에이전트가 내부 기여가 아닌 외부 기여로 사과할 때 인지 신뢰가 덜 손상되지만 인간 유사 에이전트에 대해서는 유의미한 결과가 나타나지 않았다.
반대로 행동 신뢰 측면에서 인간과 유사한 에이전트가 자신의 잘못을 완화하는 것보다 인정할 때 사람들이 조언을 더 잘 따르는 것으로 입증되었지만 기계와 유사한 에이전트에 대해서는 이렇다 할 결과가 드러나지 않았다.
두 에이전트 모두 잘못을 인정했지만 인간과 비슷한 에이전트만이 손상된 신뢰를 회복하고 사용자들이 조언에 더 잘 따르도록 유도해 참가자들에게 더 많은 점수를 줄 수 있다는 점이 흥미롭다.
이는 [기계에 가까운] 경우는 변화 가능성이 낮다고 간주하고 (de Visser 등, 2016) [사람에 가까운]의 경우 변화할 것으로 간주되었기 때문일 것이다.
'AI , 컴퓨터 , 대학원 > 논문 책 리뷰' 카테고리의 다른 글
| [어떻게 해야 하는가 ≠ 어떻게 하고 싶은가 ] 딜레마 개발 논문 2편 (2) | 2022.02.16 |
|---|---|
| [논문] 딜레마 개발 _ 간호사와 의사 간의 윤리적 딜레마 사례개발과 간호사의 의사결정 양상 (3) | 2022.02.14 |
| [논문] 귀무가설, 대립가설 이란? (2) | 2022.01.17 |
| [논문]WiFi-VLC Dual Connectivity Streaming System for 6DOF Multi-User Virtual Reality 엣지 컴퓨팅 / VLC / SNR / 관련 영상 모음 (0) | 2021.11.20 |
| [연구] 투명 물체를 인식하게 가르치다 ! Learning to See Transparent Objects (0) | 2020.10.10 |



